Overview
Properly designing high-availability (HA) web applications on the Cloud is a difficult task due to the overwhelming number of components and failure scenarios that can arise. In the real world, there is a large variance between deployments because virtually every web application has its own set of requirements. RightScale has developed solutions for the most common use-cases. By no means is this document meant to be an inclusive guide that will explain every type of scenario. The purpose of this guide is to discuss several of the most common components and also show some best practices when designing a web server architecture for a high-availability site. It will also highlight elements that you should consider when designing such architectures. An architect should carefully examine each component of their application and ensure that it is properly load balanced, fault tolerant, and scalable.
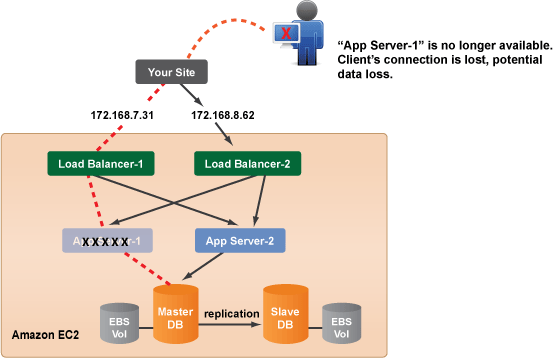
The most basic architecture that will provide a high-availability is the following 3-tier setup. It is a load-balanced 6-server setup with fault tolerance and database backups that are stored as EBS Snapshots.
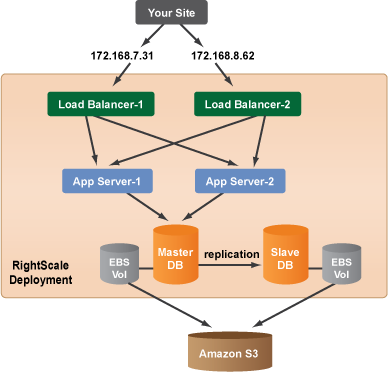
Now let's take a close look at each tier.
FrontEnds / Load Balancers
Depending on the complexity of your site, you could either have FrontEnd servers that act as your load balancers and application servers or a more complex setup where the amount of incoming traffic warrants the use of two dedicated load balancers.
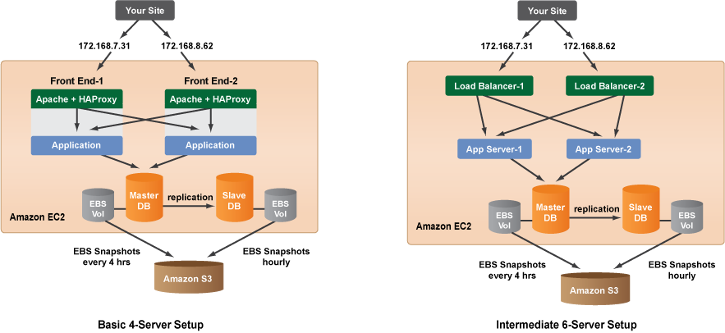
Load balancers (LB) provide many advantages to serving client requests directly from your application servers, because they allow you to better control how traffic is handled in order to provide optimal performance. Most importantly, load balancers distribute requests between application servers and monitor them to ensure that client requests are always directed to a healthy machine.
RightScale has found HAProxy to be the highest performance, most reliable and dependable software load balancer, especially when you need to scale very quickly. When HAProxy is used in conjunction with Apache, it allows you to handle SSL connections and filter incoming requests to serve static content locally or direct traffic to one or more server arrays. This additional use of Apache adds a lot of flexibility with only a negligible amount of latency. Our default load balancers are configured to run in this manner.
By default, clients round-robin through the load balancers by a DNS A-name record. In the unlikely event that a load balancer goes down, clients will simply retry the next address returned after a browser-specific timeout. You can also configure a hot-swappable standby, which monitors your load balancer's and assumes the A-record or elastic IP of a downed machine.
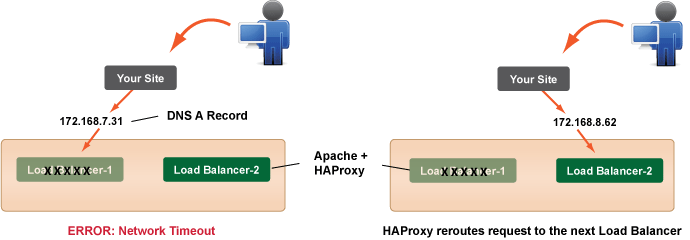
Under normal conditions, there is no need to scale the number of load balancers because two of these servers can handle a very large amount of traffic. However, if you do need to automatically scale your load balancers, this can be done by creating two scripts. One that registers and deregisters A records with your DNS provider when your servers are launched and when they are terminated. The second script loads an HAProxy config when it is launched.
Application Servers
In order to design a robust application in the Cloud, you need to ensure that it will be able to gracefully handle machine failure. What happens if one of the application servers is unresponsive?
If your application does not require session persistence, then this is not a concern, since the load balancer will be able to detect this condition and remove the faulty server from the rotation, ensuring that user requests are always sent to a healthy machine.
However, if your application does require session persistence, then you will need to properly address this issue. Generally, the best solution is to store session data in the database. This allows clients to transparently move between application servers while maintaining their session state. HAProxy is able to tie a user to a specific server throughout the duration of their session.
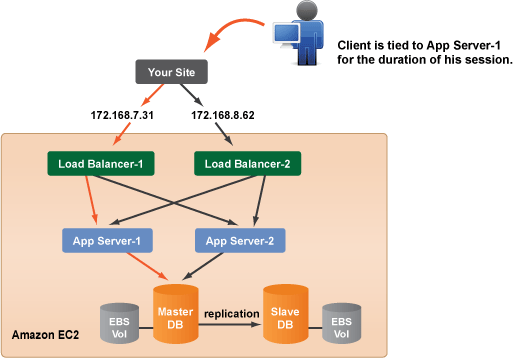
While this may be good enough for some applications, it can cause clients to lose their session if an application server becomes no longer available due to accidental termination or an automatic scale-down
of your application server array.
It's important to think about session persistence when performing the following tasks:
- Autoscaling - When you set up a scalable application server array, it is usually best to
scale-down
(terminate servers) using alerts that are based on CPU Idle Time. If a application server is not idle, there are probably active sessions that would suddenly be lost if the server was terminated. By default, application ServerTemplates from RightScale are automatically configured to connect/disconnect from the load balancer(s) whenever a server is lauched or terminated. See the Set up Autoscaling using Voting Tags tutorial for more information. - Upgrading Application Servers - When you upgrade software on your application servers, you should launch new application servers (with the latest software) and terminate the old application servers once all sessions have been ended. As a best practice, you may want to keep the old server running for an extended amount of time to ensure that no active sessions are accidentally terminated, while all new traffic will be sent to the new application servers.
Database Servers
For the majority of web applications, it is absolutely essential to run a reliable database. RightScale provides the necessary master/slave ServerTemplates that are already preconfigured for automatic replication and regular backups. They are also designed to easily handle a variety of failover scenarios, such as a failure of the Master-DB.
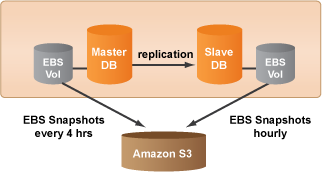
By default, the database ServerTemplates perform asynchronous replication so that your database is always present on two live servers (i.e. Master-DB, Slave-DB). If you are using one of the MySQL-EBS setups, backups of your database will be stored as EBS Snapshots. Any database restore will use one of the previously saved EBS Snapshots to restore the data.
There is also a promote to master
operational script on all RightScale database templates, so that any slave
server can assume the master
role simply by running one script on the server. This script makes it easy to recover from a failure of the master database server. By default, promoting a slave to master is a manual process. Although you can write a script that will automatically failover your database, it is not a recommended practice. Remember, the database is the core component of your site. If for some reason the data on a Master-DB becomes corrupt or there is a sudden failure, it is usually due to a serious problem. It is best to investigate the problem and perform any major actions to your database yourself. For instance, if the data on your Master-DB is corrupt and you promote the Slave-DB, you could be promoting a database that is also corrupt. As a best practice, you should always try and roll forward
by manually promoting a slave (if the database is uncorrupted) or launch a new database server using the most recent EBS snapshot (that is not corrupt).
If your application is read intensive, then the best way to scale is to launch multiple slaves and have your application round-robin its reads through these slaves using a DNS A-name record. If you have a static number of slaves, this can be done with the default templates. However, if you want your slaves to scale, you will need to create a script that will register and deregister A records when your servers launch and when they are terminated.
If you are running a non-relational database, such as MySQL cluster, then you can simply add more nodes into your deployment.
If you are running a relational database then usually the best way to scale your database is to run multiple master/slave pairs. This is typically the only way to increase the amount of writes that your deployment can handle. This requires partitioning your database and having your application decide which master to direct requests to.
MySQL proxy and Master/Master architectures do NOT allow you to increase your writes.