Overview
The following sections cover the various aspects of designing and implementing EC2 failover architectures in RightScale.
Elastic IPs and Availability Zones - Best Practices
As cloud computing continues to evolve many questions arise around the best way to design a highly reliable site on the cloud with failover and recovery. As a system administrator you must always plan for failure. This document will help explain the best way to create affordable and reliable sites on EC2 using Elastic IPs (EIP) and availability zones.
Elastic IPs (EIP) and availability zones are two key tools for creating stable architectures. An Elastic IP (EIP) allows users to allocate an IP address and assign it to an instance of their choice. Elastic IPs are dynamically re mappable IP addresses that make it easier to manage servers in the cloud because each IP address can be reassigned to a different instance when needed. An availability zone is essentially a regional data center on EC2. In the Dashboard, you have the flexibility of specifying an EIP and availability zone when you launch a server on EC2, which gives you the ability to create basic to complex site architectures that satisfy your site's cost and reliability requirements.
There are several factors to consider when designing your site's architecture
- Cost vs. Reliability - How much are you willing to invest in your site architecture and reliability?
- Performance - How does your site perform if your deployment is set up across multiple availability zones?
- Site Downtime - How much downtime am I comfortable with in a failure scenario?
The answers to these questions will help determine how you design your site. But, if you pick the wrong design, don't worry because you can easily change architectures at any time. That's the beauty of cloud computing! You are no longer limited by your physical hardware. You only pay for what you use.
The table below highlights the key differences between 3 sample architectures.
| Architecture | Cost | Downtime | Comments |
|---|---|---|---|
| Basic | $ | 5-10 min | EIPs with 1 Avail. Zone and a backup deployment (ready to launch) |
| Intermediate | $$ | Minimal | EIPs with 2 Avail. Zones (few instances in zone 2) |
| Advanced | $$$ | None | EIPs with 2 Avail. Zones (duplicate setup in zone 2) |
Architecture Cost Considerations
Remember, you only have to pay for what you want. There are several different ways to design a highly reliable site. However, it depends on how much you're willing to pay for what level of failover and reliability.
- Data transferred between instances in the same availability zone on EC2 costs $0.00 per GB.
- Data transferred between instances across different availability zones on EC2 costs $0.01 per GB.
- Creating a deployment is free. You can always create a clone of your production deployment that is ready to be launched in a different availability zone if the primary availability zone ever fails.
- See Amazon for a breakdown of Availability Zone Pricing.
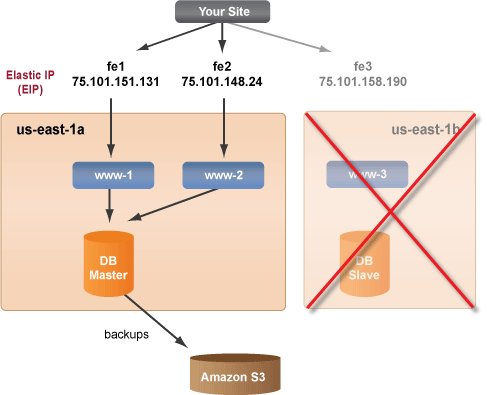
Basic Failover Architecture
The production deployment runs in a primary availability zone. A backup clone
deployment is ready to be launched in a different availability zone if the primary zone fails. This is the most affordable failover option, because deployments are completely free. Simply create a clone of your production deployment and save it as a backup deployment. If the primary zone ever fails, all you will have to do is manually launch the backup deployment. The estimated downtime would be about 5-10 minutes after you launch the backup deployment, plus any additional time that is needed to load the database. When launching the backup deployment, make sure that the appropriate EIPs are associated with the new frontend instances.
In the example diagram below, the production deployment is live and running while the backup (clone) deployment is already configured in the Dashboard and ready to be launched in a different availability zone if there is a failure in the primary zone and your production deployment disappears. The Master and Slave databases will be restored with the same backup file so that they are identical copies. However, since database backups are saved to S3 every 10 minutes, you may lose some data. If you cannot afford to lose data, you should consider using a more advanced failover architecture. Notice that the same EIPs will be used, except they will point to the new instances.
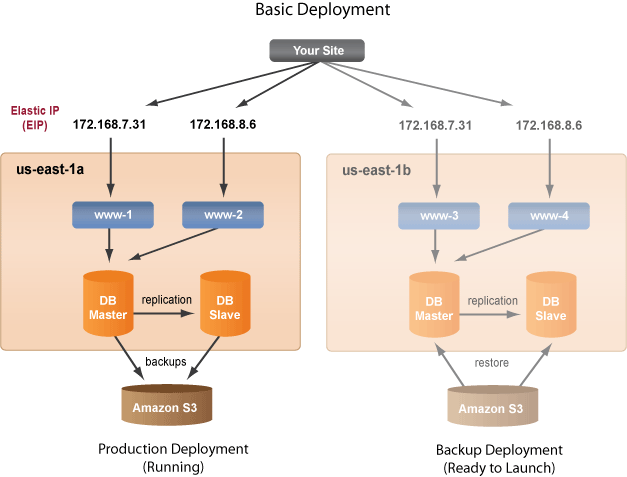
Follow the instructions below to set up the Basic Failover Architecture. This setup has a production deployment where all of the instances are running in the same availability zone. This is the most affordable failover architecture on EC2 because data transferred between instances in the same availability zone is always free. A backup (clone) deployment is unactivated, but is ready to be launched into the us-east-1b availability zone. If there is a failure in us-east-1a, you must manually launch the backup deployment. As a safety feature you cannot automate the launching of a deployment. Remember, deployments are free. You can create and configure as many deployments as you want and you only have the pay for usage time if those instances are ever launched.
Setup Instructions - Basic Failover Architecture
- Once your production deployment is running as expected, make a duplicate of the production deployment by clicking the the Clone button at the deployment level (Manage > Deployments).
- Rename the cloned deployment and call it
Backup
. - The next step is modify the backup deployment so that it launches the new instances into a different availability zone (us-east-1b). Other than changing the availability zone, everything else should remain unchanged.
- Click on an instance's nickname and click Edit.
- Select
us-east-1b(for example) from the Availability Zone dropdown menu and click Save. - Repeat this process for each instance in the backup deployment.
- Check to make sure that your two frontends are using the same Elastic IPs as the production deployment and that the
Associate IP at launch?
box is checked.
Congratulations! You now have a backup deployment that is properly configured to launch into a different availability zone for failover situations. All you have to do is click the start all
link to launch all the new instances in the deployment.
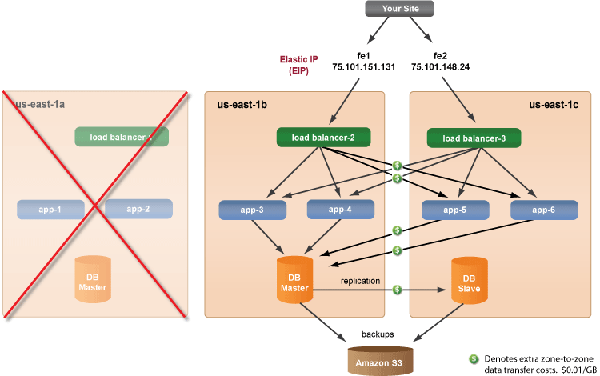
Intermediate Failover Architecture
If your production deployment cannot afford a 10 minute downtime and you are willing to invest more for added redundancy, then you can set up a slightly diversified deployment across two availability zones. In this example, we have placed the Slave-DB in a different availability zone. This may be an ideal setup if you do not have a lot of data being transferred between your application and database, and you are willing to pay for the extra instances and usage. Remember, data transferred between instances across different availability zones will costs $0.01 per GB.
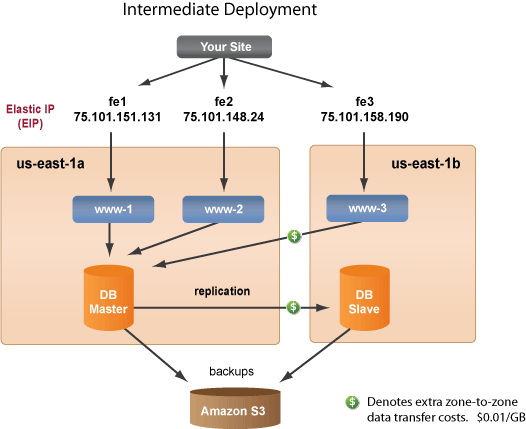
Follow the instructions below to set up an Intermediate Failover Architecture. This setup has a production deployment where instances are running in more than one availability zone. In this setup, there are three front ends using Elastic IPs. If there is a failure in the primary availability zone (us-east-1a), you will still have a running front end instance that is serving content from the secondary availability zone (us-east-1b). Simply promote the Slave-DB to Master
and launch your backup deployment in a different availability zone (us-east-1c). Obviously, the performance of the site will suffer proportionally during an availability zone failure, but the site will remain operational until you can launch additional front ends and a new Slave-DB. Remember, if you have instances running in multiple availability zones, you will have to pay for the zone-to-zone transfer fees. Data transferred between instances across different availability zones on EC2 costs $0.01 per GB.
In this example, we will use DNS with multiple A records. One A record is created for each EIP with the same DNS name. The DNS server will provide the rotation of A records.
Setup Instructions - Intermediate Failover Architecture
Production Deployment
If you follow the diagram above as an example, you will use an Elastic IP for each frontend and the Slave-DB and FrontEnd-3 are in a different availability zone. Make sure that you selected the correct Availability Zone for each server.
WARNING! The current default for a server's Availability Zone is -any-.
Now that you have an operational production deployment distributed across multiple availability zones, you should create backup instances that are ready to be launched in a failure scenario. It is important to be proactive when designing your deployment for quick failover and recovery. Remember, since you only have to pay for instances that are launched, it's a good idea to create backups
for each instance that are properly configured and ready to be launched in a failure scenario.
For an intermediate setup like the diagram above, we recommend creating backups of each type of instance that are ready to be launched with the appropriate Elastic IP and into the appropriate availability zone. Once your deployment is running, simply clone each type of instance. In this example, you should have the following two backups:
- Front end server (www-4)
- Slave-DB instance
WARNING! You should not use the start all
link once you've added backup instances.
Notice that the backups do not have Elastic IPs or Availability Zones predefined because you do not know where you will launch these instances when problems occur.
You will not have a backup for the Master-DB because you have a redundant MySQL setup. If the Master-DB ever fails, simply promote the Slave-DB to Master-DB and launch a new Slave-DB instance. By configuring these instances ahead of time, you'll be ready to launch
when problems occur.
Failover Scenarios
Failure in Primary Availability Zone (us-east-1a)
In this example, the us-east-1a Availability Zone stops providing service, but your server is still up. You have provided a deployment configuration that is tolerant of a one-zone failure.
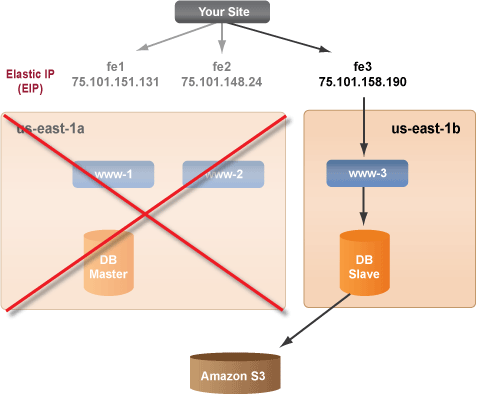
Recipe for Recovery
The first step is to get back to full performance and then add back a zone failure tolerance as a second step. During this recipe, service is never interrupted.
- Promote the Slave-DB to Master-DB.
- Launch a new front end server (www-4) in the same zone as the existing server (www-3) and assign one of the Elastic IPs that was used by one of the terminated servers.
- Launch a new front end server (www-5) in a different availability zone (us-east-1c) and assign the other Elastic IP that was used by one of the terminated servers. (WARNING: You will be charged for cross-zone data transfer costs.)
- Launch a new Slave-DB instance in a new availability zone (us-east-1c). Use operational scripts to attach the new Slave-DB to the current Master-DB to restart redundancy and replication.
- After a suitable delay, it would be a good time to take a backup of the Master-DB and examine your backup.
Once again you have a distributed production deployment spread across multiple availability zones. Remember, performance will be affected proportionately if a zone stops, but the important thing is that your service will continue to perform.
Failure in Secondary Availability Zone (us-east-1b)
In this example, all that has happened is that our redundant zone stopped performing.
Recipe for Recovery
In this recipe we will replace the failed server to reestablish high reliability. During this recipe, service is never interrupted.
- Launch a new front end server in a different availability zone (us-east-1c) using the Elastic IP that was used by the terminated front end server in us-east-1b. See Assign an Elastic IP at Launch.
- Launch a new Slave-DB instance in the same availability zone (us-east-1c). Use operational scripts to attach the new Slave-DB to the current Master-DB to restart redundancy and replication.
- After a suitable delay, it would be a good time to take a backup of the Master-DB and examine your backup.
Once again you have a distributed production deployment spread across multiple availability zones. Remember, performance will be affected proportionately if a zone stops, but the important thing is that your service will continue to perform.
Advanced Failover Architecture
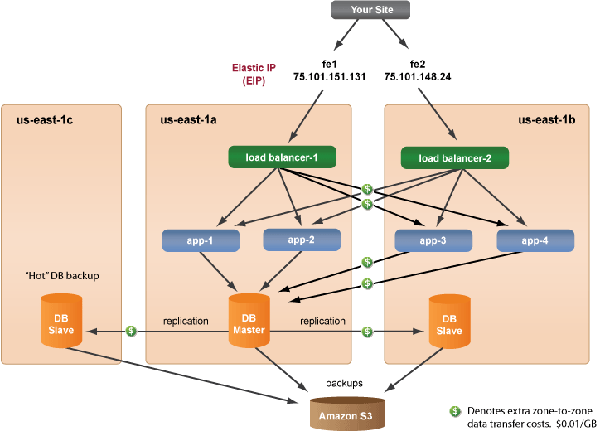
If your production deployment requires the highest level of reliability with as close to 100% uptime as possible, you definitely have the flexibility to design an extremely reliable architecture, but you must be willing to pay for the extra redundancy. In this setup, a single instance can be deleted at any time and the site will continue to operate normally and does not require any responsive action. If an availability zone completely fails, you will still have a completely functional site running in a different availability zone. However, the cost of running this type of deployment on EC2 will double, plus the data transfer costs between availability zones. From a performance perspective, your users might experience a slightly slower performance since data is sent across different availability zones, but you'll have an extremely reliable architecture on the cloud.
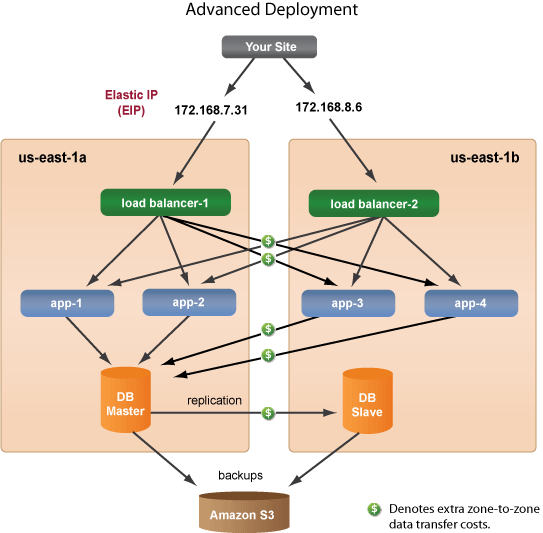
If you are using an advanced deployment architecture and the availability zone that contains your Master-DB fails, all incoming requests will automatically be rerouted to load balancer-2 and serve content from Slave-DB in us-east-1b. Visitors to your site might experience slower performance, but your site should remain fully functional. When you are ready, you can promote your Slave-DB to Master-DB and then launch a new load balancer, app servers, and a Slave-DB in a new availability zone. Notice that the EIP that was previously pointing to load balancer-1 (172.168.7.31) is now pointing to load balancer-3 in us-east-1c. When an EIP is reassigned to a different instance, it will take approximately 3 minutes for an EIP address to be transferred to a new instance. The WaitFor
feature inside our Run RightScripts ensures that the EIP is fully settled before it receives any requests.
Setup Instructions - Advanced Failover Architecture
Production Deployment (us-east-1a)
If you follow the diagram above as an example, your production setup will consist of two active deployments with another deployment configured to launch in another zone. Each deployment will be dedicated to a particular zone. Notice that you're using an Elastic IP for each frontend load balancer with the same number of application servers in each availability zone. The clone operation makes this duplication a one-click solution (with a few adjustments later).
For advanced architectures, it's better to think at the deployment level, instead of at the individual server level. Instead of creating backups for each type of server, you can simply create backup deployments that are ready to be launched in a different availability zone if one of the zones stops. Once you start thinking of collections of servers are a Deployment Unit
the move from Zone to Zone is a simple operation. Simply click the Clone button for a deployment and change the availability zones for all servers accordingly.
All of the servers in your account with the same network options are on the same local network even when in distinct deployments.
Failover Scenarios
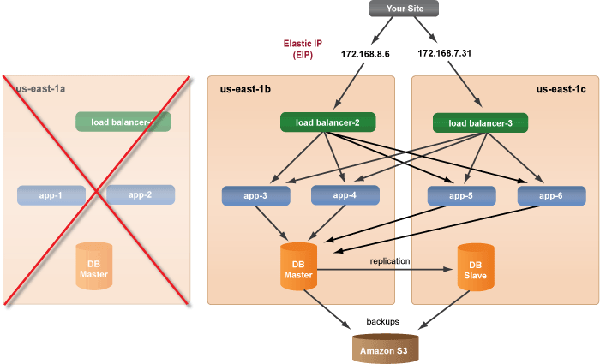
Failure in Availability Zone (us-east-1a)
Recipe for Recovery
In this recipe, you do not want to launch the entire deployment at the same time. Do not use the launch-all
button because it's important that the servers in the backup deployment are launched in the correct order.
- Go to the backup deployment (Production 1c). If the availability zone with the Master-DB fails, promote the Slave-DB to Master-DB. If the Master-DB is still operational, proceed to Step 2.
- Launch the Slave-DB into the new availability zone (us-east-1c). Use operational scripts to attach the new Slave-DB to the current Master-DB to restart redundancy and replication.
- Launch the application servers (app-5, app-6) into the new availability zone (us-east-1c).
- Launch the frontend load balancers (FrontEnd-3) into the new availability zone (us-east-1c).
- Execute the LB get HA proxy config operational action on the new load balancer (FrontEnd-3) to get the configuration file from the running load balancer in order to establish communication with the application servers. If this RightScript is not used in your FrontEnd's ServerTemplate, you can import the latest version of the
Rails FrontEnd
ServerTemplate from the MultiCloud Marketplace to gain access to this script. You can either add the RightScript as an operational script or run it as anAny Script
on the server. - Associate the unused Elastic IP to the new load balancer (FrontEnd-3).
Notes
If your Master-DB is large and takes a long time to start from backups, one advanced strategy would be to keep a Slave-DB hot
by keeping one slave up and running in as many zones as you can afford.
In a failure scenario (or heavy load), the extra backup Slave-DB will already be connected to the load balancers and application servers, and be ready to serve a larger percent of the traffic. Most application servers launch quickly and can be added as needed. These spare slaves
make a great place to test backup restore policy and QA new software. Occasionally you can restore a Slave-DB and check to make sure the data is correct. It provides a great place to perform these types of audits.