Overview
When you experience a server failure in the cloud, it's important that you remember to always roll forward
instead of trying to fix the problematic server. The important thing is to get the production site back to a stable state. Later you can troubleshoot the bad server and properly diagnose the cause of the problem without having to worry about site downtime.
Steps
For example, let's say one of your FrontEnd servers becomes problematic and stops serving traffic. All of a sudden your site is running at 50%. How do you resolve this problem?
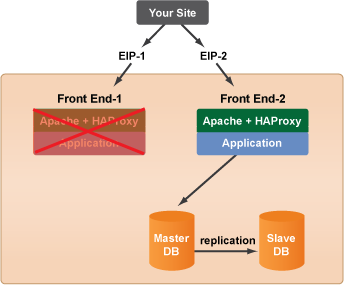
- Clone the operational Front End server (
Front End-1
). Rename itFront End-3
server. - Assign the new server the Elastic IP of the down server (EIP-1) so that it inherits the EIP at boot time. Launch the
Front End-3
server.
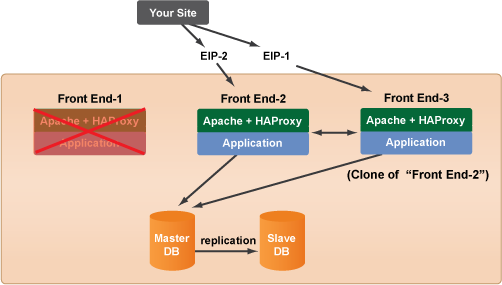
- As a safety precaution, disconnect the
Front End-1
server from the load balancer (if it's still connected). Run theLB app to HA proxy disconnect
RightScript on theFront End-1
server. You do not wantFront End-2
to continue sending requests to a bad server. - Connect
FrontEnd-2
andFrontEnd-3
servers to each other by running theLB Application to HAProxy connect
(exact name may vary) RightScript onFront End-3
so that it will properly load balance across both frontend servers. - Once the site is stable you can go back to the
Front End-1
server and properly diagnose the problem. It might be useful to keep the bad server up and running to perform various tests. Use the monitoring features and audit entries to help you diagnose the cause of the problem. Once you've finished your diagnosis, shut down the server. The key advantage of the Cloud and RightScale is that you can dramatically reduce the amount of site downtime in the event of a server failure. Instead of wasting time trying to fix a problematic server, now you can quickly replace it and then troubleshoot the problem at a more convenient time.